Scraping Slack Webhooks from GitHub
2019-02-12Some time ago, Slack became a really popular tool for instant messaging within companies and communities. Many people consider it an awesome platform; many people consider it nothing more but a glorified IRC replacement. Technical merits and flaws aside, Slack and the many similar platforms are probably here to stay for some time.
One of the things that make Slack really useful for teams is being able to quite easily write integrations connecting it to other services. Probably the simplest integration one can make in an Incoming Webhook, which is basically a gateway allowing to post messages to given team's Slack workspace by making a POST request. Webhooks do not use any additional authentication – if you know the URL, you're free to use it.

Some time ago, a colleague of mine wrote a script that would go to the Facebook profile of a nearby bistro,
scrape the page for today's menu, and post it to our workplace's #lunch channel.
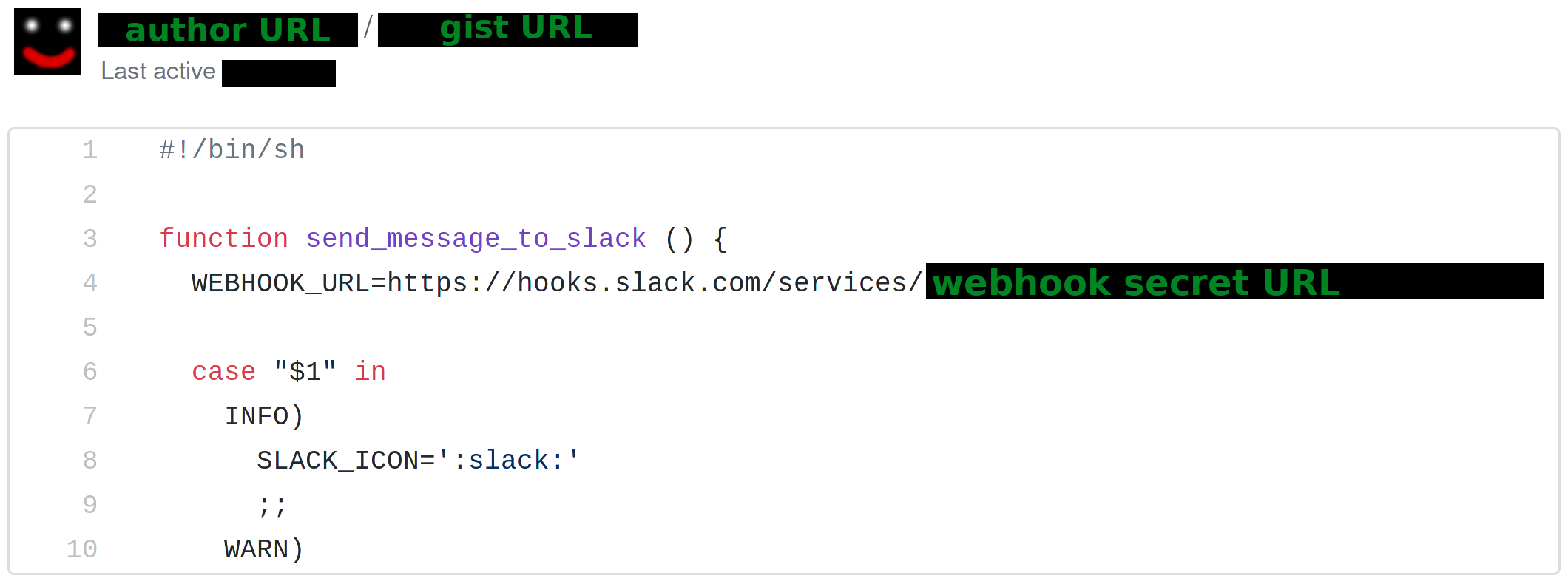
Satisfied with his work, he put the source code in a GitHub Gist, posted it on Slack, and asked for reviews.
The code seemed clean enough, and all the important parameters – including the webhook URL – were
put into consts at the beginning of the file.

After eyeballing the page for a short while, one thing caught my attention – I was not logged in at GitHub, yet I could read the Gist without any problems. It dawned on me that this had to be a public Gist, which meant it was accessible to anyone, and that anyone could take the webhook URL and use it to post messages to our #lunch channel.
As minor of an issue as it may be, I immediately notified said colleague and he quickly revoked the webhook and requested a new one for the script. But it got me thinking: how many more people have made a similar mistake? Could I scrape GitHub for public webhook URLs and use them for nefarious purposes?
Only one way to find out...
Finding relevant Gists
First things first, I fired the GitHub Gists page and typed hooks.slack.com/services into the search box.
To my amusement, almost a thousand matches were found (the number increased to slightly over a thousand since I began to write the article).

Seeing such a large data set ripe for the taking, I headed over to the GitHub API documentation to get info on how to fetch Gists I'd be interested in. Alas, it turned out that the API doesn't provide any way to search for Gists. Time for some good ol' scraping, it is.
Scraping the Gists
The search page displays the usernames and gist names with some pretty prominent hyperlinks, so extracting the gist URLs from the HTML markup was a breeze. After interating throught a few pages of the search results, I had a list of gists I could then scrape.
Since I was only interested in extracting the Slack webhook URLs, I didn't bother figuring out how to get gists in raw format and just fetched the HTML versions linked from the seach pages. Besides, a gist can contain multiple files, and the raw download option is single-file only, whereas the HTML version contains the whole gist. Either way, once the gist was downloaded, getting the Webhook URL was just a matter of using a single regex.
Hitting the rate limit
Having written the code to scrape the search pages and gists themselves,
I fired up the script. Unsurprisingly, I quickly hit the rate limit.
My first solution was just to add a --request-delay option that would allow me
to specify the number of seconds between requests. This seemed to work...
...for some time. I hit the rate limit again.
This time I decided to add some code that would check if the server's response
contained either the Retry-After or the X-RateLimit-Reset HTTP header
and then wait the necessary amount (or, if neither of these headers were present,
just some pre-determined amount). With this addition, the script could finally
work fully without any supervision. Satisfied, I went on to do some other chores
and then fired up the script before going to bed so it could work overnight.
Filtering the list of webhooks
I woke up in the morning to a list of about almost 1000 URLs... or so I hoped. Turns out the majority of results weren't actual Webhook URLs, but just placeholder strings; think something like:
hooks.slack.com/services/YOUR-WEBHOOK-ID-HEREAfter filtering out the obviously bogus entries, I ended up with a pretty number of 111 webhooks – roughly 1/9th of the original number. Not nearly as exciting, but still quite satisfying.
Contacting Slack
Having compiled the list, I was left wondering what to do next. Initially I thought about looping through the webhooks and posting a message to each of them, informing that I've scraped the URL and advising people to replace it, but I've quickly dismissed that as too invasive.
I eventually decided to simply use the contact form found in Slack's help pages, as they most probably have some procedures in place, saying how to handle this kind of stuff. A day or two after writing the message, I received the following response:
We periodically scan public GitHub repos for API tokens that could be compromised but not particularly for webhooks as, as you said, it's a minor threat as they only have posting permissions.
Nonetheless, we really appreciate that you've complied and shared this list with us. I'll make sure to forward with the rest of the Platform team so they can investigate and take any necessary actions.
Seeing how this exchange took place almost a year ago and I have received no followup, I guess Slack either decided this is a non-issue, or it's just such an everyday thing for them that a hundred more public links isn't anything worth a special mention and response.
But wait, is there actually any threat?
While it's hard to disagree that Webhooks, which can only post messages, offer pretty much no cracking leverage, they can still be used to poke at the weakest part of any security system – humans, that is. One thing I haven't mentioned yet is that while each Webhook has a name and an avatar, these are only the default values; you can easily override them by adding some extra properties in the request JSON.
{
"icon_emoji": ":robot_face:",
"user_name": "IT departament auto-messaging tool",
"text": ":exclamation: *WARNING* :exclamation:"
}While you can't get rid of the little APP badge, indicating it's an automated message, there's nothing preventing you from using a #lunch-bot Webhook to post messages to the #announcements channel, or even better – from sending personal messages to individual users, which gives ample opportunity to engage in some old-school phishing.
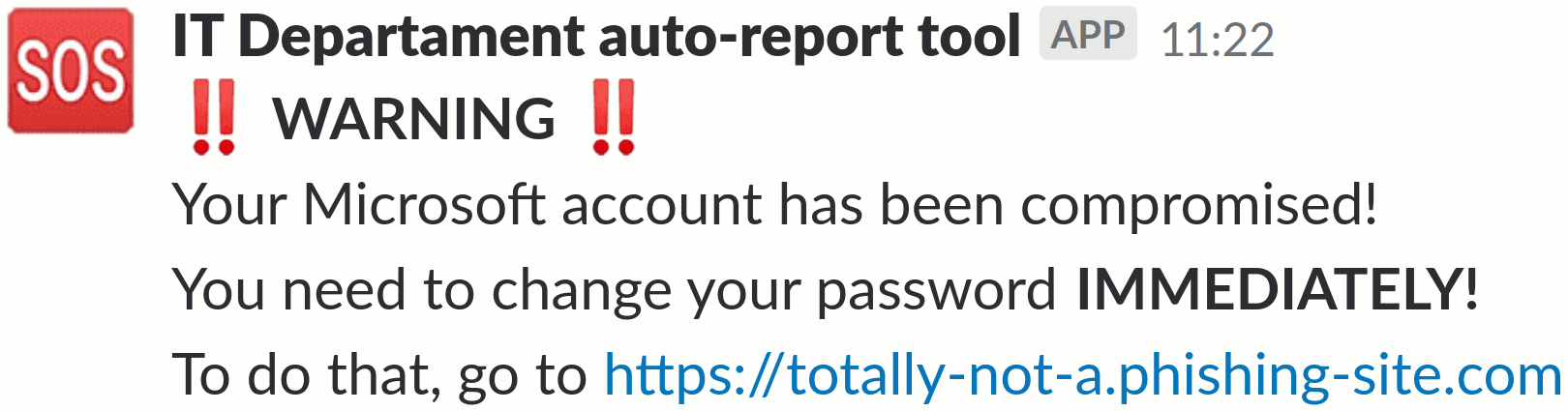
Of course, launching a successful phishing attack comes with its own set of challenges, so just because there is some phishing potential, doesn't mean that Webhooks are all bad and we should avoid them. Quite the contrary, they are an easy-to-use and useful tool. But as with any tool, they can be abused, so if you know that you may have leaked a Webhook URL somewhere – I'd recommend replacing it, just to be sure.
Comments
Do you have some interesting thoughts to share? You can comment by sending an e-mail to blog-comments@svgames.pl.